Recently I decided to individually thank each and every one of the top 100 contributors to Rails, and I wrote some software to make it feasible (almost).
I got the idea from a tweet:
Someone should start a blog where they just talk about different Rails contributors in the top-100-by-commits of all time. Just list their major features/bugs/commits, let 'em know we love 'em and all they're doing and have done.
— Nate Berkopec (@nateberkopec) April 2, 2019
This seemed like good karma. Plus, back on my old blog, I think I picked up an overly curmudgeonly reputation, due to various rants. The rants were never as angry as they were perceived as being, so I don't have a ton of regrets about that, but there is one: if you worked hard to build Rails, you made a huge contribution to my career — not just finanically but in terms of my ability to enjoy my work — and I want people to know I appreciate that.
There's another reason I felt like I was the person to take on this challenge. A reply to the original tweet suggested making it a daily thing:
100 days, 100 devs
— Richard Schneeman 🤠 (@schneems) April 3, 2019
Through a fanatical kind of over-embrace of the Seinfeld calendar, I've gotten pretty good over the years at just taking on new daily habits and seeing them through. So I knew from experience that committing to write a blog post every day for 100 days would be something I could do.
Speed Bumps
In practice, though, there were a couple speed bumps. First, I started with the top 100 contributors as listed on GitHub. But Rails is older than GitHub; in fact, GitHub was built on Rails. So because Rails started on CVS, moved to Subversion, and then moved again to git, the top 100 contributors on GitHub aren't exactly the top 100 contributors. This led to me accidentally thanking an extra person, but I think that's a good problem to have. Anyway, Rails has a special contributors page to solve this, and it also solves related problems that GitHub's automated analysis can't, like giving proper credit to developers who've had multiple usernames over the years.
Next, the top 100 listing doesn't actually run from 1 to 100. For instance, in yesterday's post, I thanked the two contributors who are tied for the #92 position. There is no #93 position; the day before, I thanked the single contributor who holds the #94 position. This is because the contributors are ranked by number of commits. If two people have the same number of commits, the Rails contributors site gives them the same ranking number, lists them in alphabetical order, and then skips ahead an appropriate number of spots when it assigns the next ranking number. Sports rankings use similar algorithms.
These issues were very easy to resolve, of course. The big speed bump was figuring out what people had done. Although a few people in the top 100 contributors are big "famous" names who speak at conferences and write blog posts, the overwhelming majority are not. So I didn't know off the top of my head what their exact contributions were. But the contributors site makes it easy for you to click on a contributor's name and see a reverse chronological listing of their commits. So initially, I just clicked commits at random to save time, but it was unpleasantly scattershot, and I knew it couldn't scale.
The 100th top committer has 75 commits. It's hard to read through 75 commits quickly and get a sense of a person's overall work. When you thank people, you want to know what you're thanking them for. If somebody spent months of their life fine-tuning Rails performance, and I wrote a blog post thanking them for the one contribution that they ever made to the view helpers, because I just happened to randomly click on that particular commit and I was in a hurry that day, that would be some pretty anemic thanking. And although you could theoretically just read all 75 commits for that #100 position, the #1 contributor in the list has 8,440 commits. It would take more than a day just to read them all, and I'd have to check my notes afterwards to figure out a consistent theme.
Naturally, as a developer, I solved this problem by writing code.
Code To The Rescue
I created a Ruby project which runs from the command line, screenscrapes the contributors site, and then analyzes Rails's commit history. I used TDD, although the specs have some flaws and my strong preference for unit tests — they're just more fun to write — led me to arguably more objects than the system really required. Anyway, the command line part of this is very easy — it just reads ARGV — but the screenscraping and git analysis are worth explaining in a little more detail.
Screenscraping
In the past, Mechanize has always been my weapon of choice for screenscraping, but I decided to try something new out of curiousity. I went with the Wombat gem. Wombat provides a succinct DSL for screenscraping and supports both CSS and XPath as further DSLs for identifying the elements on a page that you want Wombat to capture.
Here's an example from the project:
def main_page
scraped = Wombat.crawl do
base_url "https://contributors.rubyonrails.org"
path "/"
contributor_ranks "css=td.contributor-rank", :list
contributor_names "css=td.contributor-name", :list
contributor_links "xpath=//html/body/div[3]/div/div/div/div/div/table/tr/td[2]/a/@href", :list
end
scraped.inject({}) do |h, (k, v)|
h[k] = v.first(100)
h
end
end
This gets us a hash of three arrays, each with just 100 elements. (The full contributors list is much, much larger; for example, I'm tied for the 1,245th top contributor slot with over 400 other devs.) From that hash of 100-element arrays, I then construct 100 ListedContributor objects, and soon after build Commit objects to match.
The contributors site lists every commit credited to a given developer, so even if the developer has had multiple usernames, or their CVS and Subversion history lists their contributions in inconsistent ways, I can still rely on the list of git SHAs to be valid.
git Analysis
Once I have the list of SHAs, I can turn that into much more detail. Here's the entire Commit class:
# the summary comes from the contributors web site; the message comes from git
Commit = Struct.new(:sha1, :summary, :date, :message, :show) do
def initialize(*args)
super(*args)
git = Git.open("data/rails")
commit = git.gcommit(sha1)
self.message = commit.message
self.show = git.show(sha1)
end
def parsed_correct_commit?
self.message[0..50] == self.summary[0..50]
end
end
The project keeps a copy of the Rails repo in a data/rails directory. It uses the Ruby git library to open up that repo in git, find each commit, and get the commit message and diff via git.show.
I use this information to drive two word frequency analyses. The code finds out what files a given contributor has edited, and how many times. It also creates a word/frequency hash of the contributor's commit messages.
That code is super easy. There's a STOPWORDS array full of common words we don't need to care about, like "the" and "this," and a filename_from_diff method which just regexes out the filename from the diff. It's really only a distinct method at all because I always want my regexes under test. The frequency code itself just builds hashes based on how many times it sees a word or a filename.
def commit_msg_word_freq
words = (self.commits.map do |commit|
commit.message.split(/\W/)
end).flatten.select {|word| word != ""}
words.inject(Hash.new(0)) do |acc, word|
word.downcase!
acc[word] += 1 unless STOPWORDS.include?(word)
acc
end
end
def filename_modification_frequency
filenames = self.commits.map do |commit|
filename_from_diff(commit.show)
end
filenames.inject(Hash.new(0)) do |acc, filename|
acc[filename] += 1
acc
end
end
I think in a future version, I may make it easy to get from the filename to the commits involving that filename — possibly by building a Rails UI around this — but it's already a huge help.
Here's what the system looks like in action:
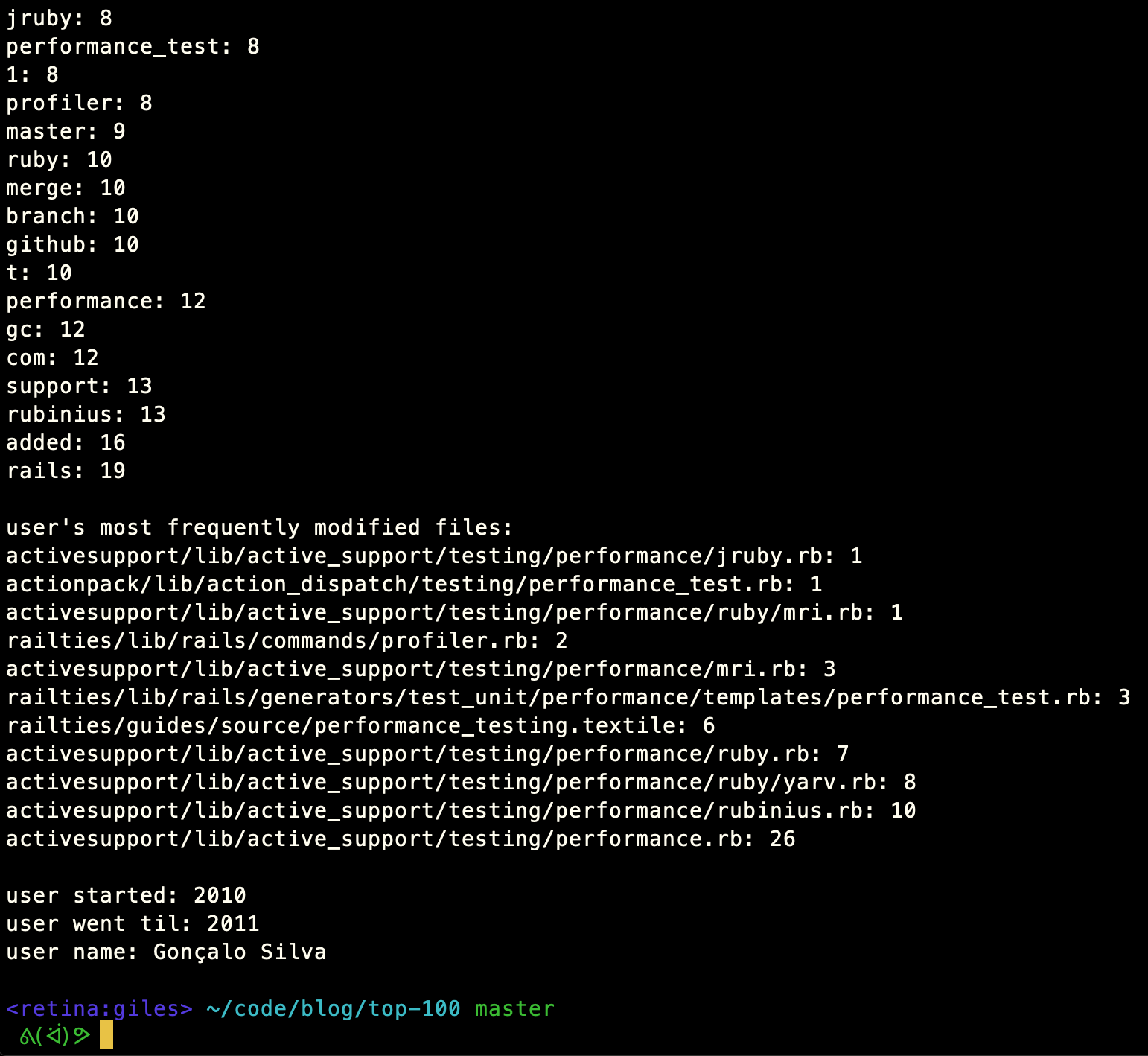
Caveat: I cherry-picked an unusually good example. Gonçalo Silva earned his spot on the top 100 contributors list with some very focused work on performance. Using this code, though, you can see that at a glance. His most frequently-used terms in commit messages include words like "gc," "performance," "performance_test," and "profiler." The only file he ever committed to which did not include the word "performance" in its pathname was profiler.rb. So, using my code, I was able to identify the consistent theme in his work very quickly.
And the thing to keep in mind is that Gonçalo had 78 commits. Although we should certainly appreciate that work — that's the whole point of this project — the top contributor has more than two orders of magnitude more commits. When I write their thank-you posts, and it's time for me to identify the themes in their work, I'm going to be very glad I have this tool.
